
作者:江南白衣,原文出处: http://blog.csdn.net/calvinxiu/archive/2007/01/31/1498597.aspx
如果说Google的搜索引擎是免费的早餐,Gmail们是免费的午餐的话,
http://labs.google.com/papers/ 就是Google给开发人员们的一份免费的晚餐。
不过,咋看着一桌饭菜可能不知道从哪吃起,在自己不熟悉的领域啃英文也不是一件愉快的事情。
一、一份PPT与四份中文翻译
幸好,有一位面试google不第的老兄,自我爆发搞了一份Google Interal的PPT:
http://cbcg.net/talks/googleinternals/index.html,大家鼠标点点就能跟着他匆匆过一遍google的内部架构。
然后又有崮崮山路上走9遍(http://sharp838.mblogger.cn)与美人他爹(http://my.donews.com/eraera/),翻译了其中最重要的四份论文:
- 《MapRedue:在超大集群上的简易数据处理》--Simplified Data Processing on Large Clusters
- 《The Google File System》
- 《海量数据分析:Sawzall并行处理》--Interpreting the Data: Parallel Analysis with Sawzall
- 《Bigtable:结构化数据的分布存储系统》--A Distributed Storage System for Structured Data
二、Google帝国的技术基石
Google帝国,便建立在大约45万台的Server上,其中大部分都是"cheap x86 boxes"。而这45万台Server,则建立于下面的key infrastructure:
1.GFS(Google File System):
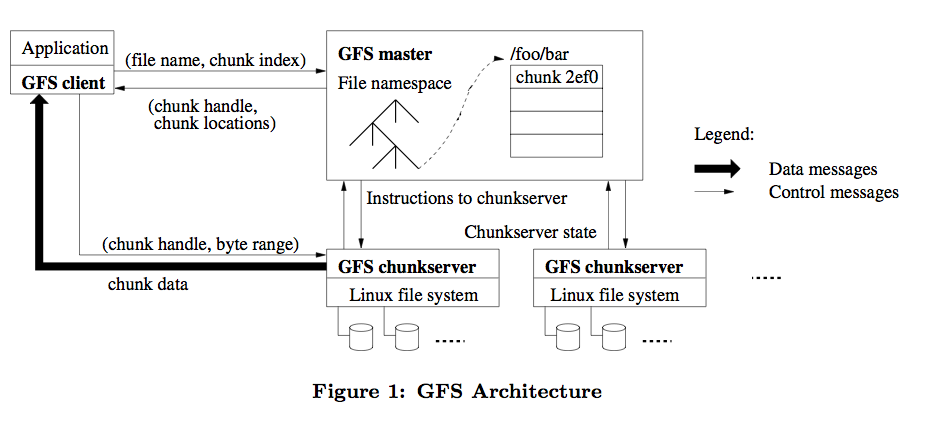
GFS是适用于大规模分布式数据处理应用的分布式文件系统,是Google一切的基础,它基于普通的硬件设备,实现了容错的设计与极高的性能。
李开复说:Google最厉害的技术是它的storage。我认为学计算机的学生都应该看看这篇文章(再次感谢翻译的兄弟)。
它以64M为一个Chunk(Block),每个Chunk至少存在于三台机器上,交互的简单过程见:
2.MapReduce
MapReduce是一个分布式处理海量数据集的编程模式,让程序自动分布到一个由普通机器组成的超大集群上并发执行。像Grep-style job,日志分析等都可以考虑采用它。
MapReduce的run-time系统会解决输入数据的分布细节,跨越机器集群的程序执行调度,处理机器的失效,并且管理机器之间的通讯请求。这样的模式允许程序员可以不需要有什么并发处理或者分布式系统的经验,就可以处理超大的分布式系统得资源。
我自己接触MapReduce是Lucene->Nutch->Hadoop的路线。
Hadoop是Lucene之父Doug Cutting的又一力作,是Java版本的分布式文件系统与Map/Reduce实现。
Hadoop的文档并不详细,再看一遍Google这篇中文版的论文,一切清晰很多(又一次感谢翻译的兄弟)。
孟岩也有一篇很清晰的博客:Map Reduce - the Free Lunch is not over?
3.BigTable
BigTable 是Google Style的数据库,使用结构化的文件来存储数据。
虽然不支持关系型数据查询,但却是建立GFS/MapReduce基础上的,分布式存储大规模结构化数据的方案。
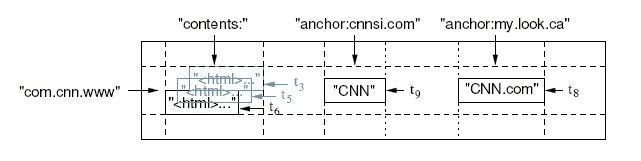
BigTable是一个稀疏的,多维的,排序的Map,每个Cell由行关键字,列关键字和时间戳三维定位.Cell的内容是一个不解释的字符串。
比如下表存储每个网站的内容与被其他网站的反向连接的文本。
反向的URL com.cnn.www(www.cnn.com)是行的关键字;contents列存储网页内容,每个内容有一个时间戳;因为有两个反向连接,所以archor列族有两列:anchor:cnnsi.com和anchhor:my.look.ca,列族的概念,使得表可以横向扩展,archor的列数并不固定。
为了并发读写,热区,HA等考虑,BigTable当然不会存在逗号分割的文本文件中,,是存储在一种叫SSTable的数据库结构上,并有BMDiff和Zippy两种不同侧重点的压缩算法。
4.Sawzall
Sawzall是一种建立在MapReduce基础上的领域语言,可以被认为是分布式的awk。它的程序控制结构(if,while)与C语言无异,但它的领域语言语义使它完成相同功能的代码与MapReduce的C++代码相比简化了10倍不止。
2 submits: table sum[hour: int] of count: int;
3 log: ChangelistLog = input;
4 hour: int = hourof(log.time)
5 emit submits[hour] <- 1;
天书吗?慢慢看吧。
我们这次是统计在每天24小时里CVS提交的次数。
首先它的变量定义类似Pascal (i:int=0; 即定义变量i,类型为int,初始值为0)
1:引入cvsstat.proto协议描述,作用见后。
2:定义int数组submits 存放统计结果,用hour作下标。
3.循环的将文件输入转换为ChangelistLog 类型,存储在log变量里,类型及转换方法在前面的cvsstat.proto描述。
4.取出changlog中的提交时间log.time的hour值。
5.emit聚合,在sumits结果数组里,为该hour的提交数加1,然后自动循环下一个输入。
居然读懂了,其中1、2步是准备与定义,3、4步是Map,第5步是Reduce。
三. 小结:
本文只是简单的介绍Google的技术概貌,大家知道以后除了可作谈资外没有任何作用,我们真正要学习的骨血,是论文里如何解决高并发,高可靠性等的设计思路和细节.....



相关推荐
《小猫的晚餐》是一个专为少儿设计的编程学习项目,使用了流行的Scratch编程语言。这个项目旨在通过趣味性的游戏场景,激发孩子们对编程的兴趣,同时培养他们的逻辑思维能力和解决问题的能力。Scratch是由麻省理工...
《小鹿的晚餐》是一个专为少儿设计的编程学习项目,使用了Scratch这一流行的图形化编程语言。这个项目的源代码文件案例素材提供了一个有趣的、互动的游戏场景,旨在引导孩子们通过编程来解决实际问题,激发他们的...
16--[小鹿的晚餐].zip源码scratch2.0 3.0...1.合个人学习技术做项目参考合个人学习技术做项目参考 2.适合学生做毕业设计项目参考适合学生做毕业设计项目参考 3.适合小团队开发项目模型参考适合小团队开发项目模型参考
5--[小猫的晚餐].zip源码scratch2.0 3.0...1.合个人学习技术做项目参考合个人学习技术做项目参考 2.适合学生做毕业设计项目参考适合学生做毕业设计项目参考 3.适合小团队开发项目模型参考适合小团队开发项目模型参考
scratch3小狗的晚餐sb3,关卡游戏,完成任务过关,比较简单
### 烧烤技术学习与开店流程分析 #### 一、引言 本文根据翟少明先生的经验分享,深入解析开设烧烤店的关键步骤和技术要点。翟少明在XX地区经营烧烤店长达十一年之久,积累了丰富的实战经验,并在当地赢得了良好的...
可以用一种委婉的方式邀请对方共进晚餐,展示诚挚的态度:“顺便说一下,下周我们能否找个时间一起吃个饭?我希望能尽快见到您。”这样的提议既显示了写信人希望修复关系的诚意,又留给双方进一步沟通的空间。 在...
公司还为员工提供丰富的福利,如免费的早中晚餐、休闲娱乐设施(如巧克力、懒人球、巨型积木)以及医疗资源(包括牙医和家庭医师),甚至为育婴假员工提供75%的薪资,体现出对员工的关怀和支持。 【谷歌的产品与...
食谱分类:按类型(如早餐、午餐、晚餐、甜点、饮品等)和难易程度进行分类,便于快速查找。 详细食谱信息:每个食谱包括配料清单、制作步骤、时间估算、营养成分、烹饪技巧及用户评论。 上传与分享食谱:用户可以...
【四年级英语下册知识点...通过这些单元的学习,学生们将能掌握基本的学校设施词汇,询问地点和时间的方法,以及日常生活活动的表达。同时,理解和应用这些知识对于提高他们的日常交流能力和英语阅读写作技能至关重要。
- `eat dinner`: 吃晚餐 - `exercises`: 锻炼(注意正确发音,分音节记忆) 2. **句型结构**: - `When do you…?`: 你什么时候……? - `At …o’clock`: 在……点钟 - `I get up at…`: 我在……起床 - `We...
- eat breakfast, lunch, dinner: 吃早、中、晚餐 - get up, go to bed: 起床,上床睡觉 - wash my clothes: 洗衣服 - watch TV: 看电视 - go swimming, running: 游泳,跑步 - do homework, kungfu: 做作业,...
在学习牛津英语四年级上册的过程中,学生需要掌握一系列基础知识,以便在期末时能够进行全面的复习和总结。以下是一些关键的知识点: 一、缩略形式与完整形式 缩略形式在日常对话中常见,如: - that's = that is -...
本文将探讨达·芬奇是如何在他的画作《最后的晚餐》中运用几何透视技术构建三维空间模型,并介绍一种反向几何透视方法,该方法可以从二维平面图(2D)重构出原始的三维空间(3D)模型。 首先,我们来了解透视技术的...
报告标题“2020-2021中国外卖行业发展分析报告”以及描述中提到的“阿里新服务研究中心x饿了么培训学习中心”显示,本报告是由阿里系的研究机构与饿了么合作发布的,重点关注了2020至2021年期间中国外卖行业的发展...
在学习《朗文英语 4A》第二章“More about our friends”后,我们需要掌握一系列重要的词汇、句型以及表达方式,以提升我们的英语水平。以下是对这些内容的详细解释: 一、新词汇及用法 1. look after your pets - ...
•如果您在授权时遇到麻烦,请务必首先执行https://github.com/manastungare/google-calendar-crx/wiki/Troubleshooting中的所有步骤。 •如果发现错误,请提交错误。不要在评论中简单地提到它,并期望它被修复 - ...
【蒸蛋技术分享】 蒸蛋是一道简单却充满无限可能的美食,无论是南方的“蒸水蛋”还是北方的“鸡蛋羹”,都是家常餐桌上的常客。下面将详细介绍这十种不同口味的蒸蛋方法,让你的蒸蛋技艺更上一层楼。 1. **牛奶...
除此之外,为了扩展读者的学习资源,书中还推荐了一些参考网站,供读者学习最新的设计趋势和技术,以及欣赏其他优秀设计师的作品,以激发自己的创作灵感。同时,每个章节后的代码解密环节,有助于读者理解背后的编程...
- **晚餐时**: - “就餐”灯光效果自动启动 - 餐厅窗帘自动打开 - 餐后自动洗碗机开始工作 - **晚间娱乐**: - “影片”场景一键启动 - 家庭影院设备自动开启 - 接听电话时影院系统自动降低音量 - **睡前**: -...